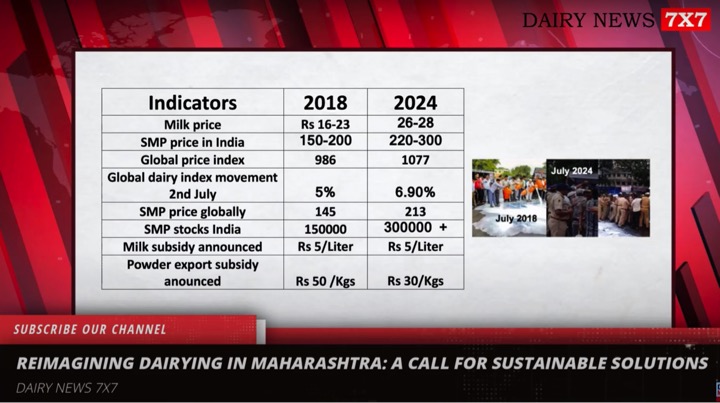
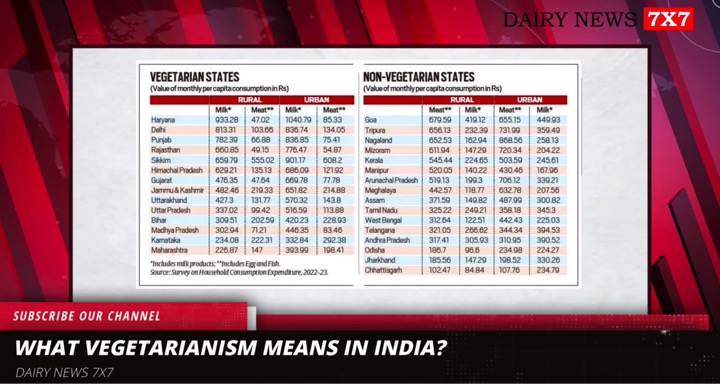
Data relevancy, adequacy and reliability determine the quality of research. Finding datasets to test and train research models is probably the first step to take before building a model.
Moreover, sometimes getting access to a dataset can throw up ideas about building a model by utilising the data.
The Centre has been putting out much of their data in the public domain. For instance, the Indian Census is the largest single source of different statistical information on various characteristics of the people of India for last 130 years.
The Census has been an attractive source of data for scholars and researchers in demography, economics, anthropology, sociology, statistics and many other disciplines. The National Sample Survey Organisation (NSSO) has been conducting nationwide sample surveys and generates data on various socio-economic aspects of the economy required by different government agencies, both Central and States since 1950.
For agricultural research also, datasets on crop and district-wise land are used; data on area, production and productivity parameters of food and non-food crops and State-wise farm harvest prices of crops are put out by the Directorate of Economics and Statistics.
Likewise, data on number of livestock along with their sex composition, age distribution, utility wise distribution etc. is provided by livestock census on quinquennial basis. This data helps in tracking breed wise growth of animal population and also in making plans and policies for growth of livestock sector. However, very little information is available on fodder in the public domain. Although, one can access data on district wise area under total fodder but there is wide discontinuity in the dataset. Further, merely information on aggregate area on fodder, without disaggregating it into important fodder crops like Berseem, Oat, Lucern etc, and various fodder grasses hides many significant information on green fodder. Many studies claim that cultivated fodders occupy only 4 per cent of the entire cultivable land in the country from the last 3-4 decades.
Deficit variation
Area under Berseem — a major rabi fodder crop in north, central and eastern region— is also being reported around 1.9 million hectare form last few decades. But the estimates of fodder production vary widely.
There is not only deficit in fodder availability for livestock, there is also wide variation in the fodder deficit estimates at national level. According to a recent study, India is facing a net shortfall of 35.6 per cent green fodder, while the latest report of Jhansi-based Indian Grassland and Fodder Research Institute (IGFRI) shows a deficit of green fodder of 11.24 per cent.
This discrepancy in fodder deficit is mainly because of the assumptions of these estimates. Therefore, future projections of fodder availability based on the current estimates may hamper appropriate policy planning in meeting fodder requirement for our livestock in coming days.
Policies to bridge this fodder deficit will be hard to formulate without reliable data on area and production of fodder from all forage sources. The Centre must conduct a nationwide survey, either yearly or on quinquennial basis, on forage resource availability as well its utilisation because it largely depends on the regional cropping pattern, climate, socioeconomic conditions and type of livestock reared. Enlarging the scope of NSSO will also be pivotal in generating the reliable estimate of area and production of fodder crops in national as well as regional context. The technical assistance from dedicated fodder research based institutes like IGFRI, Jhansi would be of great help in this direction.